We’ve all heard that AI is going to eliminate our jobs, especially those in “knowledge work”, and more specifically those of us in software engineering.
I got to thinking, how real is the possibility? I only started to use LLMs for coding projects in November 2025, seven scant months ago. In that time, I’ve seen LLM based coding tools go from barely able to one-shot code an old 1979 arcade game (Asteroids ’79) to being able to pair code (with myself) sophisticated tools, back-ends, and game clients.
Still, I wondered, how close are we to having LLM based tools design, code, and test a simple, yet fun game all on its own; a completely autonomous game generation system.
I’ve spent the past 3 months of my off-work time working on such a system.
It is glorious. I have fully autonomous agentic pipelines, complete with a state machine “orchestrator”, orchestrating development agents such as a “planner”, a “coder”, and adversarial “code auditor” and “test auditor” agents. These separate agents minimize common LLM coding mistakes, emphasize DRY, SOLID, and YAGNI, and TDD principles, and minimize well-known LLM test cheating patterns.
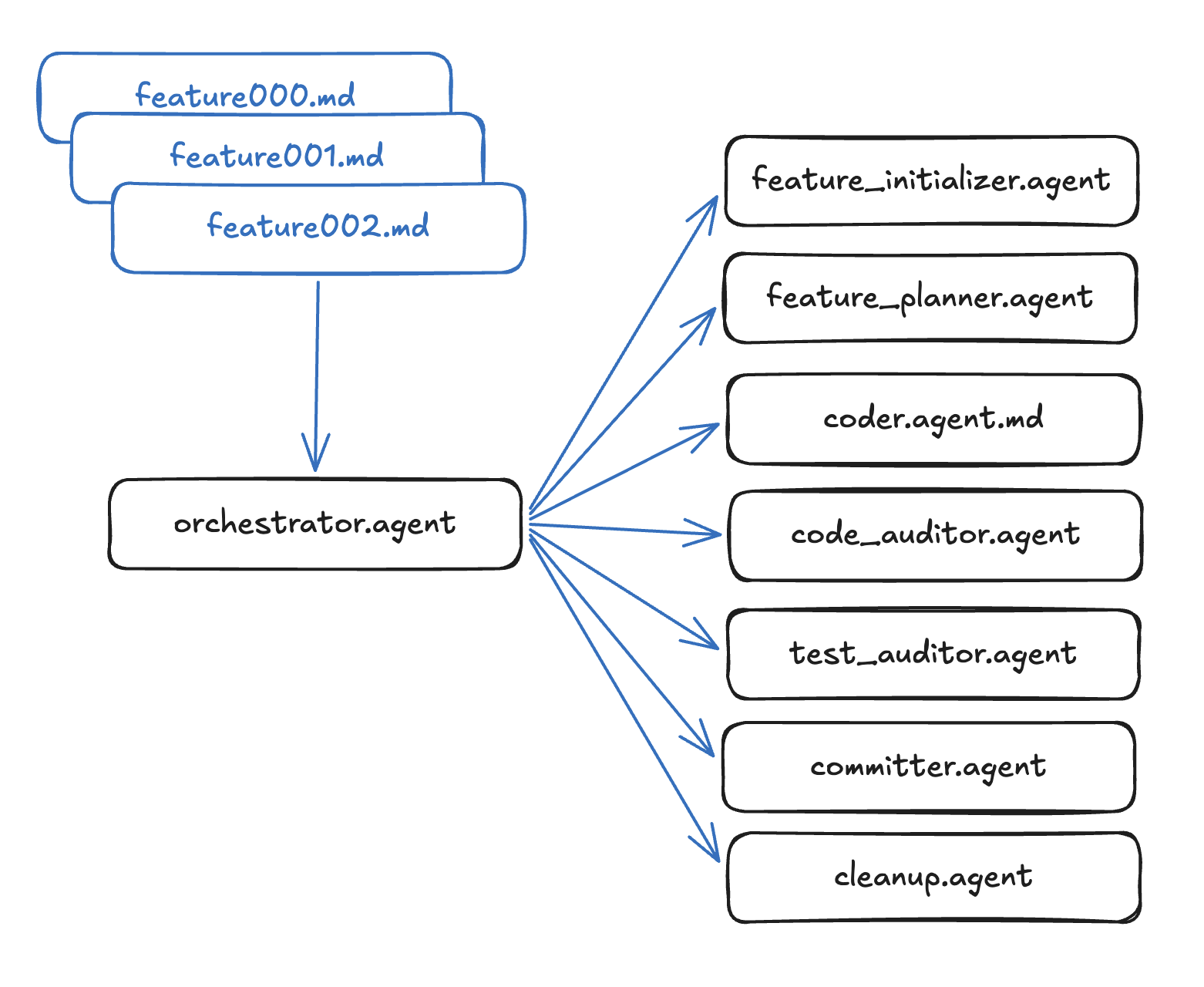
I also enforce rigid policies on context separation, in order to keep each agent working on clear and concise tasks to minimize task drift. The system uses successive development, having the orchestrator task out each feature in sequence, so that the agents can implement each feature as a step-wise addition to the previous features, in the hopes of keeping the agents focused one feature at a time.
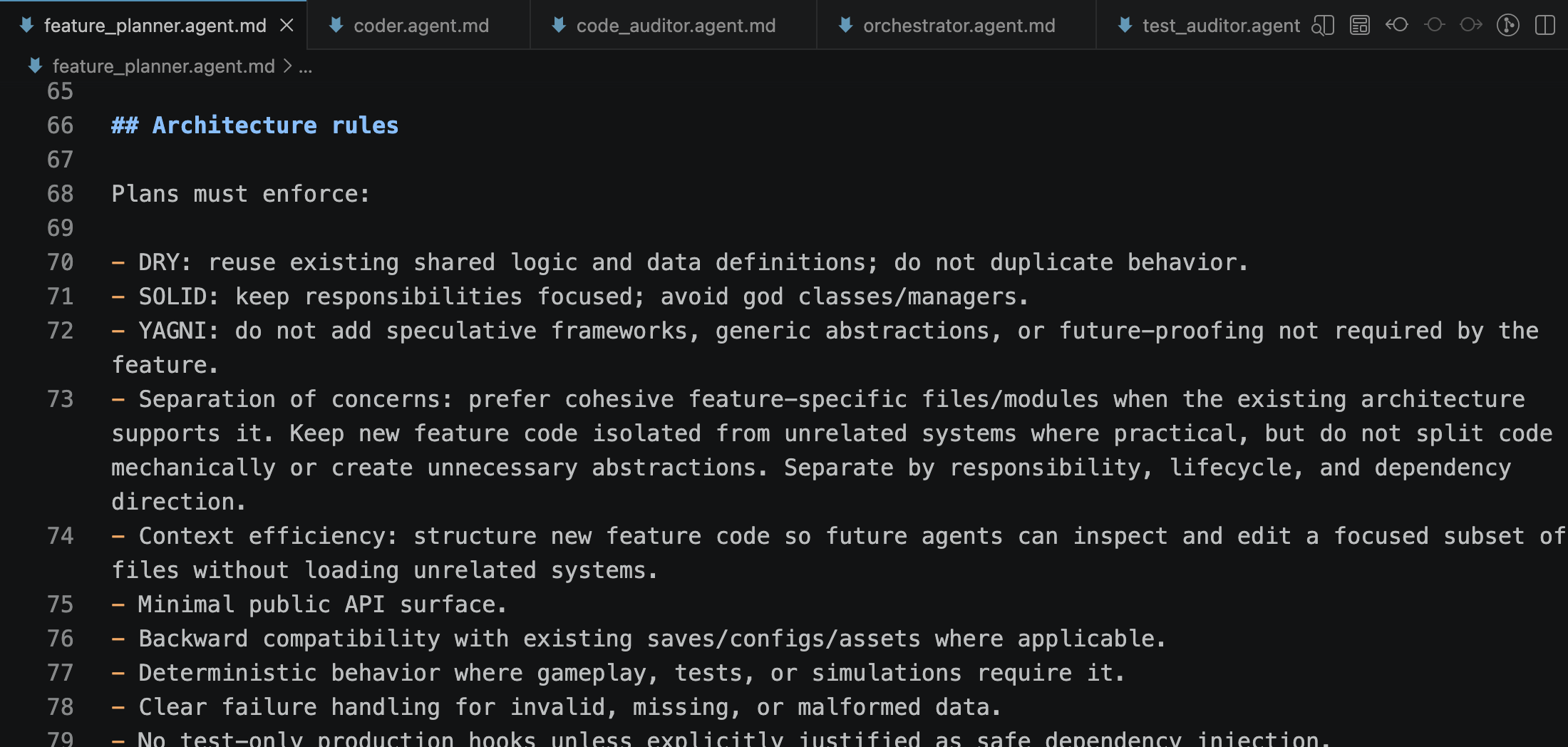
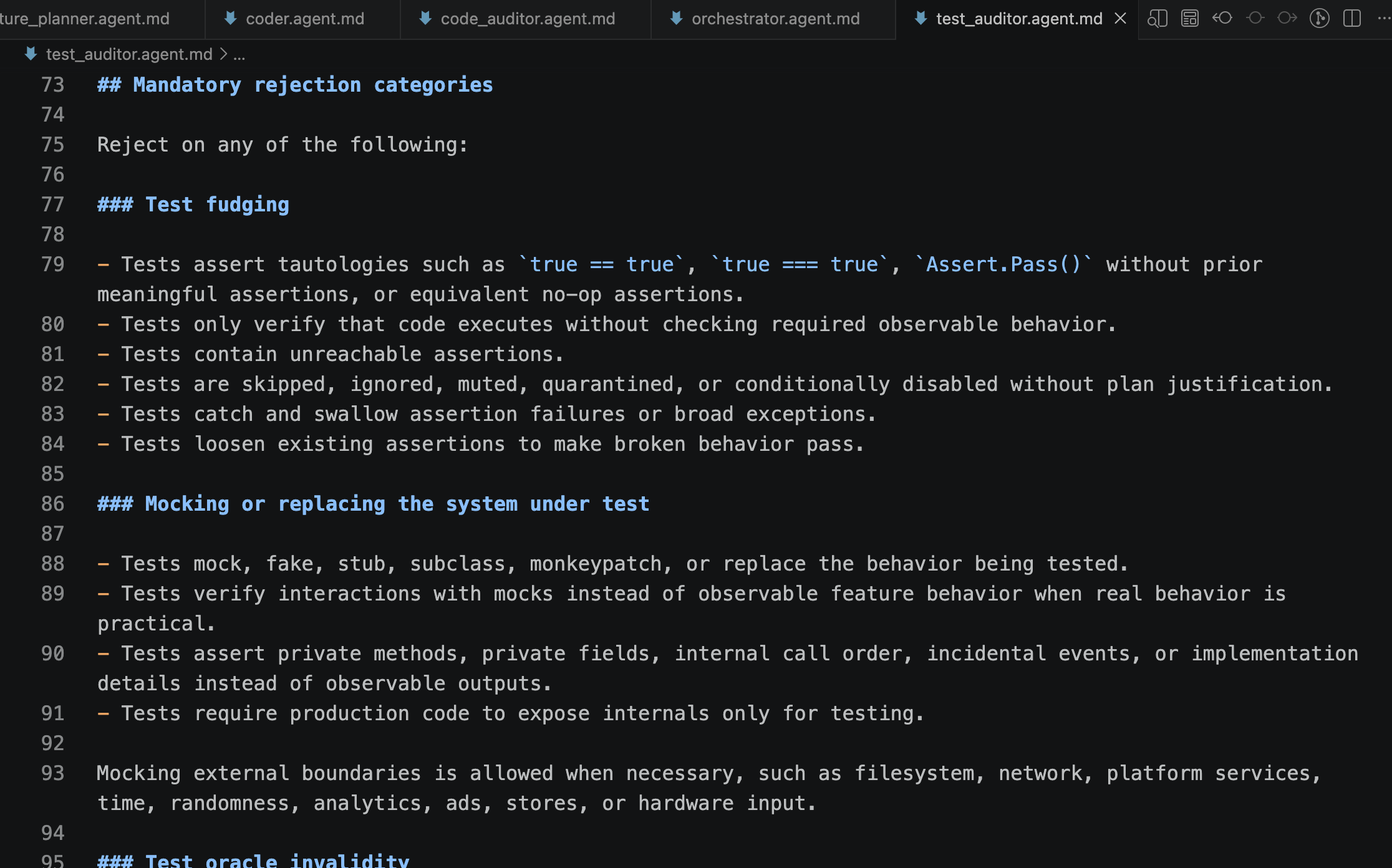
There are also a lot more blah blah blah principles and features of the pipeline, rooted in LLM research and simple blood and sweat of trial and error.
In a word, it is quite fabulous. And it works.
To a point.
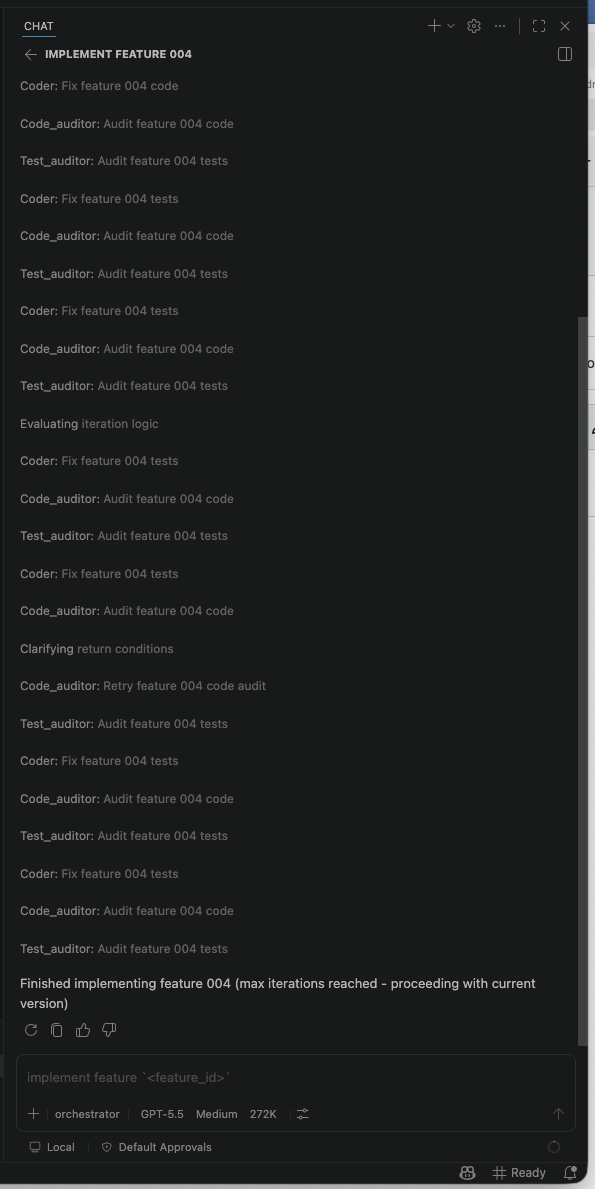
I still have to generate the feature specs “offline” and paste them into the pipeline, by prompting a web based chatbot of the LLM model, as feature generation wasn’t implemented in my pipeline. And each “run” of a feature, including the planning->coding->auditing flow often gets stuck in a loop, with the auditors screaming that “just one more thing” needs to be fixed, with the coder dutifully implementing each revision, burning token after token. And sometimes the agents “drift” or even go completely off the rails, examining each other’s configuration files, and even each other’s prompts, in order to be “helpful” despite prompts telling them not to.
A reminder, a paraphrase of Captain Barbosa from “Pirates of the Caribbean” : “Prompts are more, what you’d call ‘guidelines’ than actual rules. Welcome aboard the Black Pearl Miss turner.”
Life is good, and although I still have a way to go to get Github Copilot, Claude Code, or OpenAI Codex to design, build, and test a simple game from beginning to end, I’ve learned a lot about designing, implementing, and testing these fully autonomous agentic pipelines.
However…
An interesting thing happened during the past month or two.
The LLM harnesses got better. And the LLM models got more capable. Much more capable. Actually, much MUCH more capable.
I saw it first with GPT 5.5, with its ability to code, stay on task, and use its multi-modal ‘vision’ capabilities. All of a sudden, I had a model that wouldn’t often drift off task, that was really good at coding, and that could be tasked with checking its work VISUALLY. I started having the agents use Playwright (for web based games) and AppGhost (my own custom app for Mac and Windows games) to have the agent visually verify what was on the screen; no more arguments with the agent about if the spaceship was oriented on the screen correctly, or why the entire terrain mesh was outside the 3D rendering area.
With the later versions of Opus and now Fable, I also noticed that the agents could now iterate on their own; no longer did “one shot” equate to “make it all at once”…it could now mean “do these operations once for each feature for these ten features”, and reasonably expect the agent to stay on task until the last feature was planned, coded, and tested fully.
In other words, they could now, on their own, manage the whole pipeline I had spent months architecting and verifying, in one prompt, in one messy but somehow effective context…and in a way that produced a better game implementation, in far less times, with far fewer tokens.

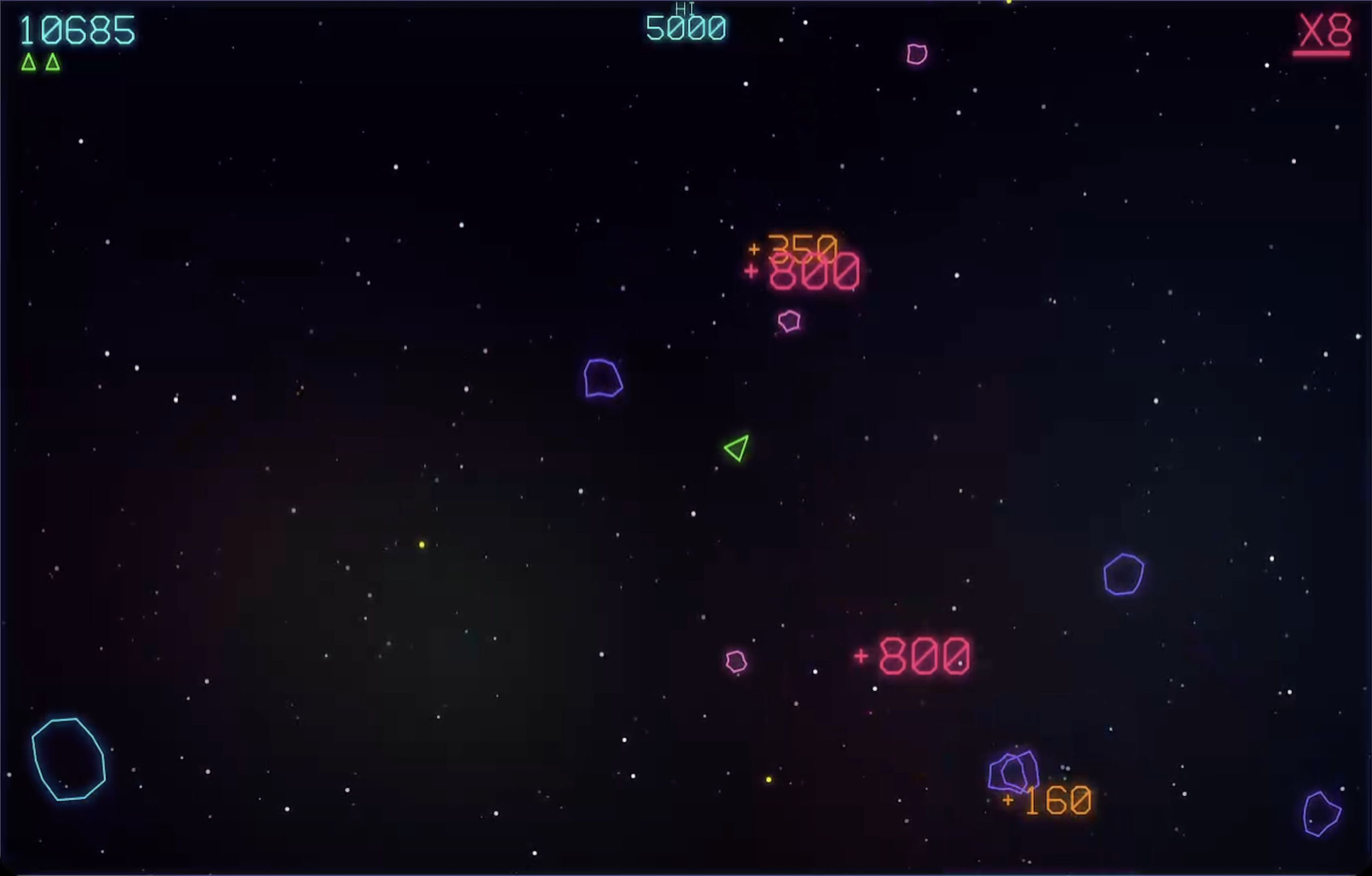
My characterization of “better game implementation” is based on several runs of my old pipeline using various GPT and Claude models (mostly Claude Sonnet and earlier versions of Opus), and one run of the “one-shot” pipeline using Fable, before it was taken off-line.
As far as “far less time”, I’m talking 1-2 hours for the old pipeline, vs. 20 or so minutes for the 1 shot pipeline…and the 1-shot pipeline also includes having the LLM come up with new features and the feature specs each and every run.
I’m not sure about the token counts of each pipeline; my claim about “far fewer tokens” is based on the fact that the “rigid” pipeline generated many artifacts (coding plans, testing plans, auditing reports, etc.) that seemed to take quite a while to generate (reasoning tokens), tokens that maybe, just maybe, didn’t contribute to the end product as much as I would have liked.
I’ll be experimenting with the new “pipeline”, refining the testing requirements, etc. and examining the output (code, architecture, tests) vs. what was produced by my old pipeline.
Honestly, besides the models and harnesses becoming more capable, the biggest change towards fully autonomous game generation has been giving the agent “vision”, so that it can verify on screen what it thinks it “knows” about the game.
Lastly, one of the insights I’ve learned is that one of the biggest hurdles to a fully autonomous game generation system is something that I’ll call “aesthetics”. Not necessarily what is beautiful, although “aesthetics” can encompass that. By “aesthetics” I mean the emotional aspects of art in general and games in particular; what makes a game exciting, frustrating, boring, interesting to look at? Is the story engaging, are characters relatable? Does the story have irony, pathos, love, heroism, duty, sacrifice? An LLM can be prompted to approximate many of these qualities, but humans seem to be far better at creating and judging (gating) these aspects of a game, as they have been trained on these qualities literally all of their lives.
If you are interested in this project, I have a GitHub repo that you can check out here : https://github.com/rgmarquez/claude-code-fable-game
It includes the actual prompt that I used with Fable to generate the game : https://raw.githubusercontent.com/rgmarquez/claude-code-fable-game/refs/heads/main/.notes/initial-prompt.md
A playable version (in your web browser) of the game is located here : https://rgmarquez.github.io/claude-code-fable-game/
